
What does risk-based CSV mean and to what extent has this approach been adopted in organizations?
In practical terms, risk-based CSV means one thing above all else: no longer treating everything the same. This is precisely where many organizations fall short. In theory, the concept is understood, but in practice, organizations often continue to play it safe when it comes to validation. This is reflected in recurring patterns: decisions are avoided rather than justified for fear of audits, and there is little difference in the depth of documentation between critical and non-critical functions. The result is a situation in which risks are assessed but have no real control effect. Risk-based CSV means exactly that – not just testing, but also co-managing. This requires the courage to make informed decisions and to defend them in audits. To achieve this, the organizational prerequisites must be created and responsibilities clearly defined. And it requires a culture in which risk decisions are accepted and supported by all. If this succeeds, the potential of CSV can be leveraged – less over-engineering, significantly lower effort, and validation that is oriented toward the reality of modern IT.

You emphasize the growing importance of lifecycle-oriented thinking when dealing with CSV. What is the challenge in establishing it sustainably?
First of all, lifecycle-oriented CSV is not a new concept. It is the pressure to implement it that is new. In practice, it fails less because of a lack of knowledge than because of a lack of operational anchoring. CSV must take place where systems are actually controlled, especially in change, release, and incident management and in collaboration with cloud and SaaS providers. Above all, this must take place during ongoing operations. The actual task – and also the difficulty that arises time and again – is to make existing concepts manageable and consistent. This means answering very practical questions: What does “validated state” actually mean after the tenth release? Which changes really need formal validation? How can the effort remain manageable? To deal with this, you don't need new processes, but clear, pragmatic rules, risk-based decision-making aids, and CSV concepts that work in day-to-day operations and not just in concept form.
What is the impact of artificial intelligence on the traditional approach to validation, and what pressure for change is it exerting?
AI does not change the goals of CSV, but rather the nature of control. It is important to take a realistic approach to AI risks. Neither excessive actionism nor rigid blockades will get us anywhere. In concrete terms, this means that traditional tests remain relevant and important. However, they alone are no longer sufficient because AI systems entail additional risks – for example, through learning behavior, data dependencies, or model changes over time. That's why validation needs to be augmented in several areas, especially through governance and monitoring concepts, performance and data quality monitoring, and, above all, through clearly defined limits on the use of the systems and their impact on the definition of decision-making logic and the structure of decision-making processes. You should therefore start by clearly classifying AI use cases, clearly defining responsibilities, and carefully expanding existing CSV and data integrity principles. My experience is that companies that address these issues early and consistently are much more relaxed during audits.
Risk-Based Validation in a Maturing Regulatory Landscape
Computer System Validation (CSV) continues to evolve as regulated environments increasingly rely on cloud technologies, agile delivery models and software-as-a-service solutions. By 2026, CSV increasingly reflects a mature, risk-based and lifecycle-oriented discipline – building on established principles and strong regulatory alignment while addressing growing system and data complexity and focussing on data, algorithms and lifecycle control. At the same time, Artificial Intelligence (AI) and personalised medicine introduce new system characteristics and data dependencies. Overall, no disruptive changes are expected in the CSV sector in 2026, but a continued evolution towards risk-based, lifecycle-oriented validation. Organizations that succeed in this environment apply established CSV principles pragmatically, integrate validation into modern IT and data architectures, and treat data integrity as an end-to-end responsibility. So, what exactly are the developments that will shape the CSV context over the coming months?
1. Risk-Based CSV and Data Integrity as an Established Foundation
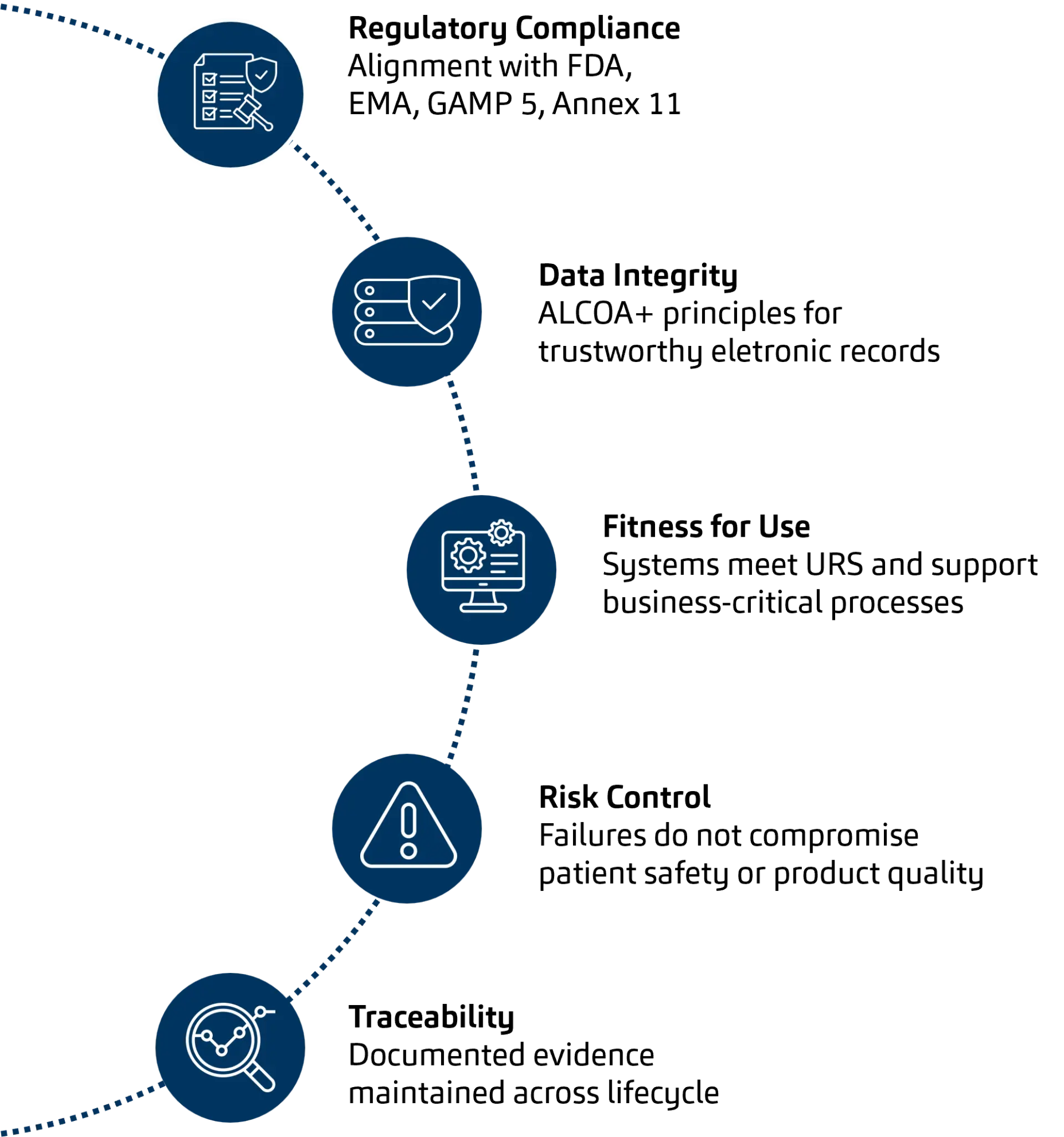
Risk-based thinking is firmly embedded in modern CSV and continues to serve as its foundation. The focus is particularly on three areas: protection of patient safety, assurance of product quality, and safeguarding data integrity. Data integrity must be given special attention here – because, despite technological change, it is increasingly becoming the linchpin and backbone of all CSV programs. ALCOA+ principles, audit trails, access control, data provenance and cybersecurity measures ensure trust in validated systems and enable innovation.
Guidance from ISPE, the GAMP 5 Second Edition and the evolving regulatory framework (including the draft revision of EU Annex 11) consistently emphasise a proportionate, pragmatic and risk-focused approach to validation. Rather than introducing new concepts, these frameworks reinforce the core objectives of software validation in GxP environments, which remain stable across technologies.
2. Cloud & SaaS: Mature Validation Approaches
For cloud-based and SaaS solutions, CSV practices have largely stabilized. These include, in particular, supplier qualification as a central validation activity, clearly defined models of shared responsibility, and validation that focuses on configuration, interfaces, and intended use. CSV increasingly supports frequent releases, patches and continuous delivery through governance, change management and lifecycle controls.
3. AI Systems: Extending Existing CSV Principles
AI-enabled systems extend CSV principles into new dimensions, including learning behaviour, model drift, explainability and performance monitoring. Traditional test-based validation is complemented by procedural, organisational and monitoring controls to ensure continued fitness for intended use.
4. Personalized Medicine & Data-Centric Validation
Personalized medicine significantly increases system and data complexity through the integration of clinical, genomic and real-world data. CSV shifts from validating individual systems to ensuring end-to-end data integrity, traceability and process control across complex data flows.
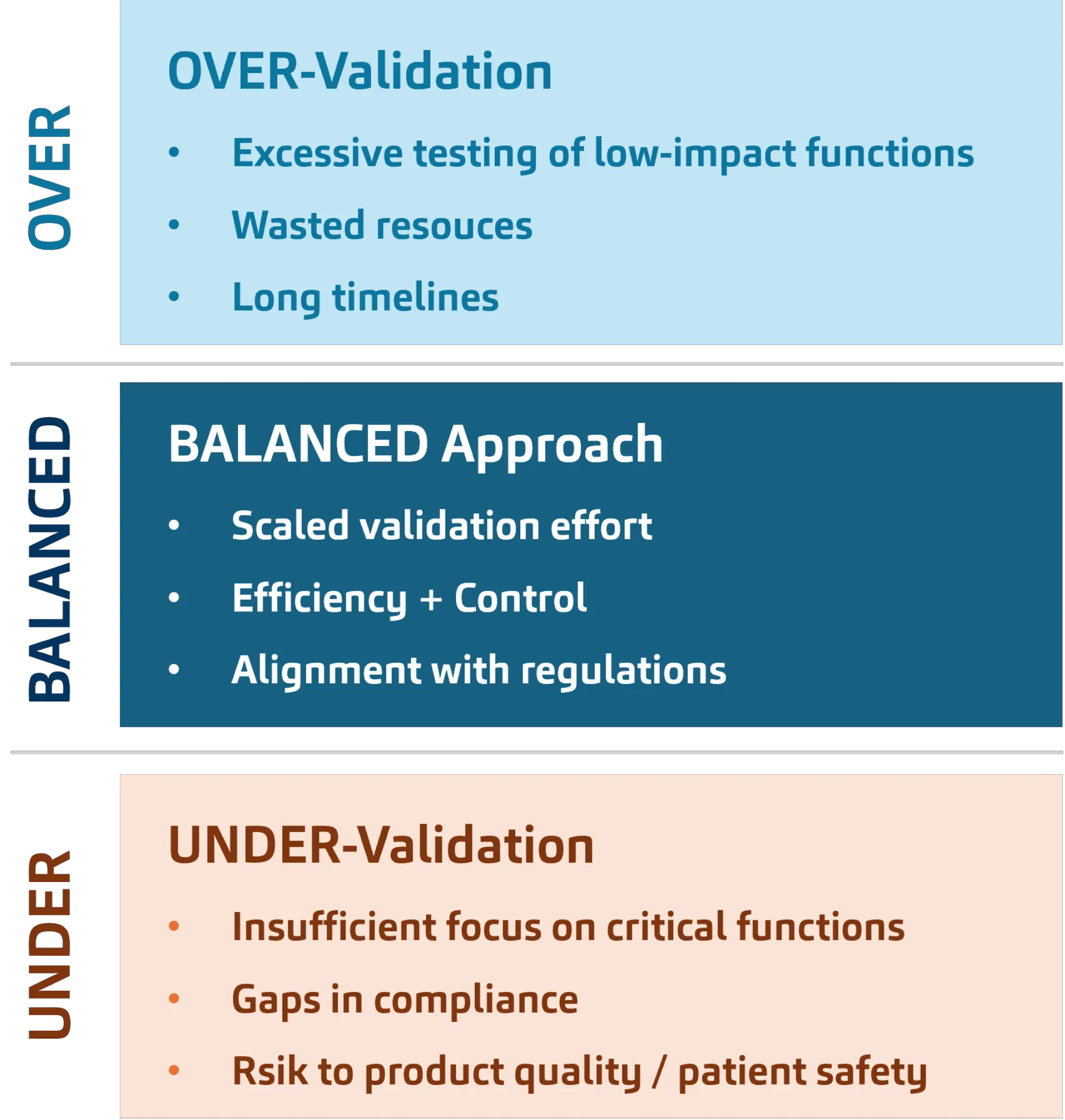
5. Lifecycle Thinking and the Right Level of Validation
CSV is increasingly understood as a continuous lifecycle discipline embedded in change and release management. A validation strategy must be designed in such a way that it avoids the typical risks in the validation process. These include, on the one hand, over-validation, which is primarily caused by excessive testing of functions with little impact and results in long timelines and wasted resources. The other extreme is under-validation. This lacks an appropriate focus on critical functions, causes gaps in compliance processes, and, above all, generates risks for patient safety and product quality.
Author
Would you like to learn more about this topic or discuss individual challenges?
Our contacta are available for a personal consultation.